
批量删除 Evicted Pods
第一种写法
1 | !/bin/bash |
更简单的写法
1 | kubectl get pods | grep Evicted | awk '{print $1}' | xargs kubectl delete pod |
Wget 下载 Oracle JDK
1 | wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-linux-x64.tar.gz |
ubuntu 容器安装 netstat ping ip ..…
1 | ifconfig |
以 root 用户进入 Container
1 | docker exec -it -u root dreamspace-jenkins bash |
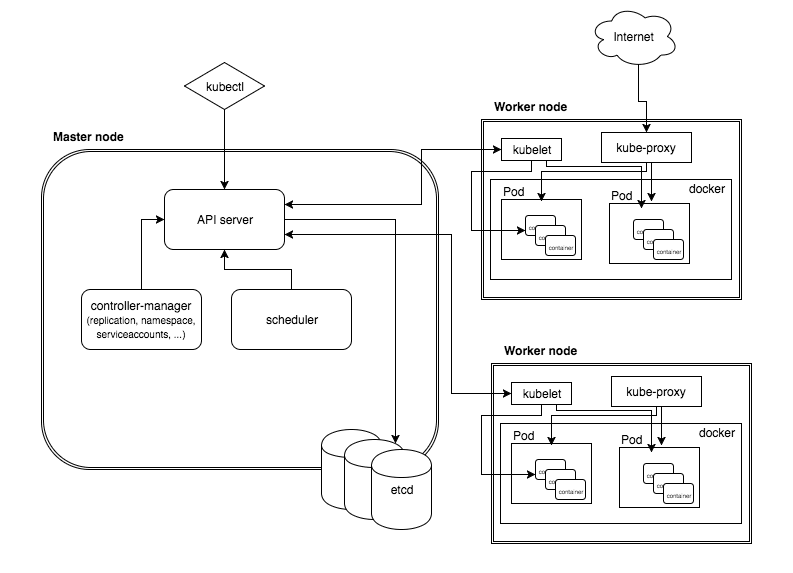
资源类型 & 创建方法 & 资源清单
1 | * 资源类型 |
控制器 Deployment
概念
- Deployment构建在ReplicaSet之上,只有Deployment可以使用声明式 ( kubectl apply -f … )
- Deployment可以手动kubectl patch, 也可以在yaml中修改后,kubectl apply -f ..…
- kubectl get rs -o wide 可以看到不同的版本,Deployment维护不同版本的ReplicaSet, 可以随时rollout,undo..…
直接patch, Json格式
1 | replicas = 5 |
蓝绿部署 Blue Green Deployment
- 目标
减少发布时的中断时间、能够快速撤回发布。
It’s basically a technique for releasing your application in a predictable manner with an goal of reducing any downtime associated with a release. It’s a quick way to prime your app before releasing, and also quickly roll back if you find issues.
- 概念
蓝绿部署中,一共有两套系统:一套是正在提供服务系统,标记为“绿色”;另一套是准备发布的系统,标记为“蓝色”。两套系统都是功能完善的,并且正在运行的系统,只是系统版本和对外服务情况不同。
最初,没有任何系统,没有蓝绿之分。
然后,第一套系统开发完成,直接上线,这个过程只有一个系统,也没有蓝绿之分。
后来,开发了新版本,要用新版本替换线上的旧版本,在线上的系统之外,搭建了一个使用新版本代码的全新系统。 这时候,一共有两套系统在运行,正在对外提供服务的老系统是绿色系统,新部署的系统是蓝色系统。
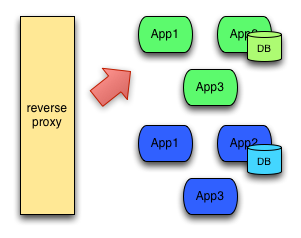
蓝色系统不对外提供服务,用来做啥?
用来做发布前测试,测试过程中发现任何问题,可以直接在蓝色系统上修改,不干扰用户正在使用的系统。(注意,两套系统没有耦合的时候才能百分百保证不干扰)
蓝色系统经过反复的测试、修改、验证,确定达到上线标准之后,直接将用户切换到蓝色系统:
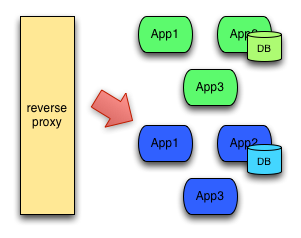
- kubernetes 做法
- Service可以有多个控制器,只要label满足条件
- 设置2个控制器,分别为老版本&新版本( 蓝绿 )
- 2个控制器label全都满足Service条件,新老版本同时存在
金丝雀发布 Canary Releases
金丝雀发布(Canary)也是一种发布策略,和国内常说的
灰度发布是同一类策略。蓝绿部署是准备两套系统,在两套系统之间进行切换,金丝雀策略是只有一套系统,逐渐替换这套系统。
- 部署新版本
1 | kubectl set image deploy myapp-deploy myapp=ikubernetes/myapp:v3 |
- 暂停
1 | kubectl rollout pause deploy myapp-deploy |
- (没有问题) 继续
1 | kubectl rollout resume deploy myapp-deploy |
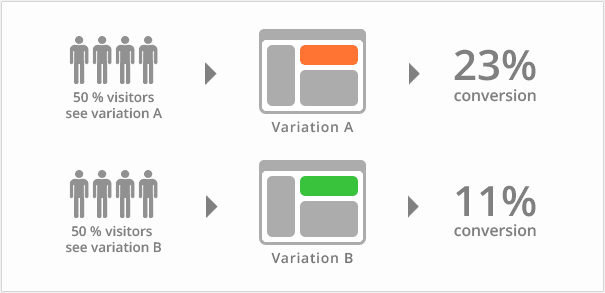
A/B测试 A/B Testing
首先需要明确的是,
A/B测试和蓝绿部署以及金丝雀,完全是两回事。蓝绿部署和金丝雀是发布策略,目标是确保新上线的系统稳定,关注的是新系统的BUG、隐患。
A/B测试是效果测试,同一时间有多个版本的服务对外服务,这些服务都是经过足够测试,达到了上线标准的服务,
有差异但是没有新旧之分(它们上线时可能采用了蓝绿部署的方式)。A/B测试关注的是不同版本的服务的实际效果,譬如说转化率、订单情况等。
A/B测试时,线上同时运行多个版本的服务,这些服务通常会有一些体验上的差异,譬如说页面样式、颜色、操作流程不同。相关人员通过分析各个版本服务的实际效果,选出效果最好的版本。
在A/B测试中,需要能够控制流量的分配,譬如说,为A版本分配10%的流量,为B版本分配10%的流量,为C版本分配80%的流量。
滚动升级
Kubernetes 中采用ReplicaSet(简称RS)来管理Pod。如果当前集群中的Pod实例数少于目标值,RS 会拉起新的Pod,反之,则根据策略删除多余的Pod。Deployment正是利用了这样的特性,通过控制两个RS里面的Pod,从而实现升级。 滚动升级是一种平滑过渡式的升级,在升级过程中,服务仍然可用。
k8s分批次有序地进行着滚动更新,直到把所有旧的副本全部更新到新版本。实际上,k8s是通过两个参数来精确地控制着每次滚动的pod数量:
- maxSurge 滚动更新过程中运行操作期望副本数的最大pod数,但不能为0;也可以为百分数(eg:10%)。默认为25%。
- maxUnavailable 滚动更新过程中不可用的最大pod数,但不能为0;也可以为百分数(eg:10%)。默认为25%。
Sample
maxSurge = 1 表示滚动升级时会先启动1个pod
maxUnavailable = 1 表示滚动升级时允许的最大Unavailable的pod个数
假设replicas为3,则整个升级,pod个数在2-4个之间
1 | 创建Deployment |
控制器 DaemonSet
概念
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
典型场景
- 运行集群存储 daemon,例如在每个 Node 上运行
glusterd、ceph。 - 在每个 Node 上运行日志收集 daemon,例如
fluentd、logstash。 - 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、
collectd、Datadog 代理、New Relic 代理,或 Gangliagmond。
kubernetes 自己也在使用DaemonSet 管理自己的组件
1 | kubectl get ds -n kube-system |
- DaemonSet 也可以滚动更新
kubectl set image ds filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpine
- 因为docker可以与宿主机共享namespace, 可以设置 kubectl explain po.spec
hostNetwork
Host networking requested for this pod. Use the host’s network namespace.If this option is set, the ports that will be used must be specified.Default to false.
- DaemonSet 每台宿主机只有一个,所以用hostNetwork来使用宿主的端口, 即不用Service也可以实现…
- 【Ingress Controller】由DaemonSet的上述功能实现
Service
CoreDNS & Kube-DNS
CoreDNS 是 Kubernetes 1.11 的默认选项。
标准CoreDNS Kubernetes配置旨在向后兼容之前的kube-dns行为。但是,通过一些配置更改,CoreDNS可以允许你修改DNS服务发现在集群中的工作方式。许多这样的功能旨在仍然符合Kubernetes DNS规范:它们增强了功能,但保持向后兼容。
CoreDNS还具有一项特殊功能,可以改善外部名称DNS请求的延迟。 在Kubernetes中,pod的DNS搜索路径指定了一长串后缀。这样可以在请求集群中的服务时使用短名称,例如上面的“headless”,而不是“headless.default.svc.cluster.local”。
在CoreDNS中,你可以使用标准DNS区域传输来导出整个DNS记录集。这对于调试服务以及将集群区域导入其他DNS服务器非常有用。
除了上述功能外,CoreDNS还可以轻松扩展。可以构建CoreDNS的自定义版本。
三类IP地址
- node network - 节点网络
- pod network - Pod网络
- cluster network (service network) - 集群网络 virtual IP
工作模式
NOTE: IPTables | IPvs 规则就是Service规则
- userspace - before kubernetes 1.1
- iptables -
- ipvs - kubernetes 1.11 默认 ipvs,不用先到 kube-porxy , 如 ipvs 没被激活,则自动降级为 iptables
类型
ExternalName
- k8s 内部 pod 访问外部服务,pod client > ExternalName > ExternalService
- ExternalName是个Name, 不是IP, 而且一定能被DNS解析
ClusterIP
- 无头, 如果设置 clusterIP: None , 称为无头ClusterIP, 不分配Clusteer IP地址,所有请求直接发送相应的pod, kube-dns解析可以得到验证.
NodePort
LoadBalancer
其它
kubectl expose … 创建service
Service 与 pods 通信
Service不会直接到pods, 中间有Endpoints, 也是标准的k8s对象
Endpoint 就是地址+端口
通常可以认为就是 Service -> Pods
资源记录的格式
SVC_NAME.NS_NAME.DOMAIN.LTD
示例:redis.default.svc.cluster.local.
LBaaS,Server负载均衡,2级调度
- 1级,LBaaS > k8s上相当数目的 NodePort ( Service )
- 2级,NodePort ( Service ) > ( Deployment ) Pods
Session 亲和性
- 分类 ( sessionAffinity )
- None ( default )
- ClusterIP
- ClusterIP: 将来自同一个客户端的请求,发送至后端同一个pod
1 | Session 亲和性 |
循环测试shell脚本
1 | while true; do curl http://192.168.1.71:30080/hostname.html; sleep 1; done |
问题
kube-dns svc.cluster.local
描述
- dig -t A myapp-svc.default.svc.cluster.local. @DNS地址 无反应
- ping不通kube-dns地址
- kube exec -it KUBE-DNS-PODs sh 可以解析地址,但有错误提示
- 查到要修改宿主机的配置文件 sudo vim /etc/resolv.conf, 因为dns容器配置从宿主机继承,但不明白为什么?
可能的原因
- Rancher RKE 安装的 k8s 集群,可能与官方 kubeadmin 的不同
- 查看官方文档 https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/
1 | 宿主机 /etc/resolv.conf: |
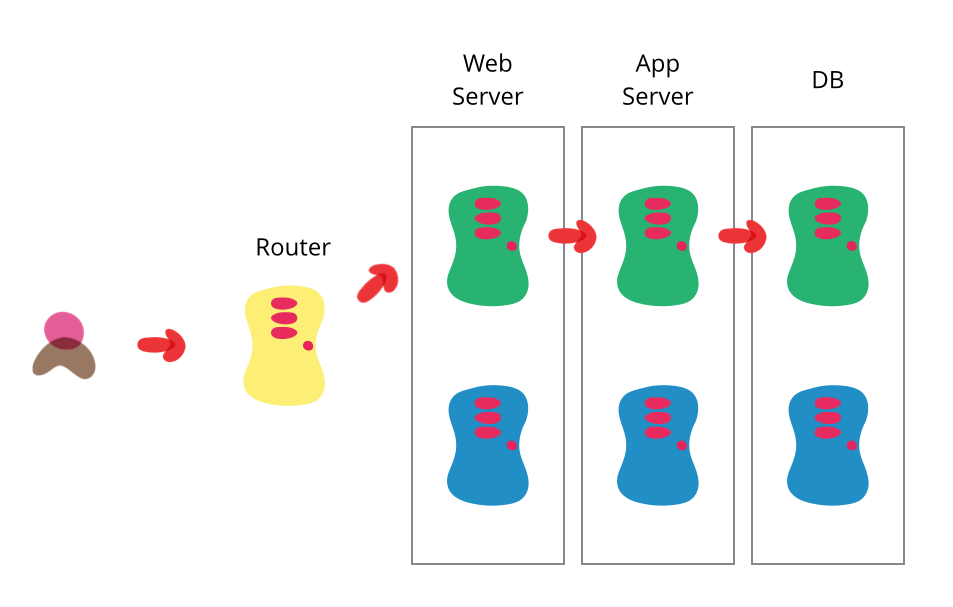
Ingress & Ingress 控制器
概念
Ingress & Ingress Controller
==Ingress== 和 ==Ingress Controller== 不同,Ingress是一种资源,Service将Pod变化发送给Ingress, Ingress将变化注入Ingress Controller
四层 & 七层
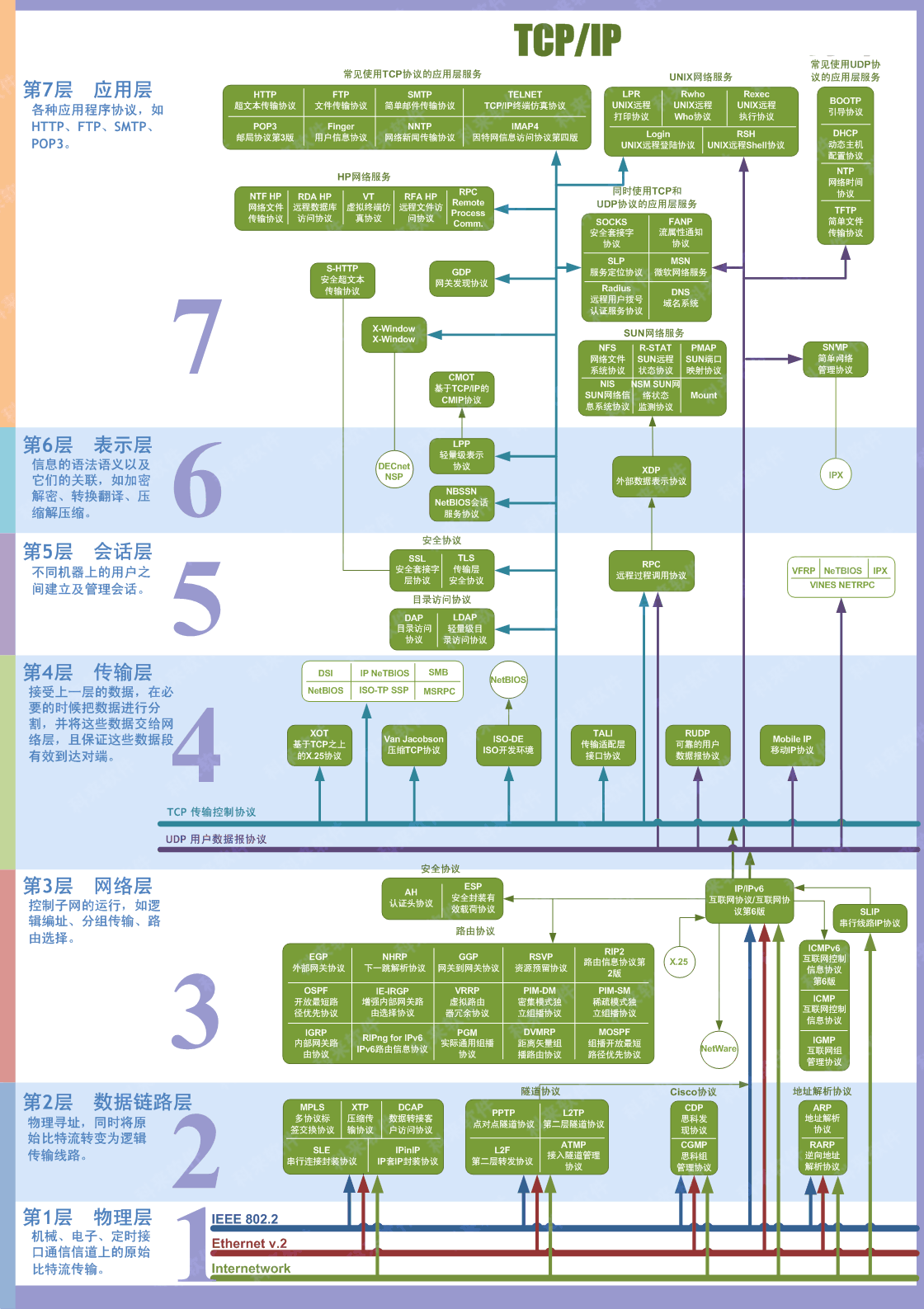
OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,因此其最主要的功能就是帮助不同类型的主机实现数据传输 。完成中继功能的节点通常称为中继系统。一个设备工作在哪一层,关键看它工作时利用哪一层的数据头部信息。网桥工作时,是以MAC头部来决定转发端口的,因此显然它是数据链路层的设备。具体说:
- 物理层:网卡,网线,集线器,中继器,调制解调器
- 数据链路层:网桥,交换机
- 网络层:路由器
- 网关工作在第四层传输层及其以上
- OSI 七层模型
问题
- 因为iptables & ipvs调度器是四层的,无法调度https,而后台server全部设置https | sso也不现实,所以需要加入新的调度器来实现
- 通常情况,如果加入新的调度器 ( nginx or others ),又会多一层,基本上是:
外置负载均衡 $\longrightarrow$ NodePort $\longrightarrow$ 七层调度器 ( nginx… ) $\longrightarrow$ Service $\longrightarrow$ Pod
解决
- Docker可与宿主机共享Namespace, 可以设置 hostNetwork 来使用宿主的端口, 不用Service(NodePort)也可以接入外部流量
- DanmonSet Controller可以做到1)每台主机只运行一个Pod; 2)只在有限的主机上运行此Pod
- 与Deployment, ReplicaSet, DaemonSet不同,不属于Controller Manager,
种类
- HAProxy 基本不用
- Nginx 最常用
- Traefik
- Envoy 微服务
映射机制
- 虚拟主机: 多个虚拟主机,对应后台多个服务..…
- URL代理: URL映射
工作流程
- Ingress 直接将请求发往Pod, 但Pod,或一类服务的Pod, 是经常变化的,还需要Service解决
- Service 负责对后台的pods分类( Labels ),识别pod有多少,IP信息等等
- 如果Servie负责的pods有变化,会及时通知Ingress( Nginx… ), Ingress将变化注入Ingress Controller, 及时刷新&重载配置
- (了解) Nginx 也可以自动刷新&重载,但不如Traefik, Envoy,后者天生就是为了适应变化的
Ingress on Rancher
- Rancher RKE 安装的 k8s, 已经有了 ingress-nginx 名称空间 ( namespace ), 并且已经有了 3 个 Ingress 控制器
- Rancher RKE安装的 Ingress Controller, 应该是第二种方式,共享主机名称空间,就是利用主机的网络端口。
- 用法, vim with-rbac.yaml
- Deployment $\longrightarrow$ DaemonSet
- spec + hostNetwork
- 保证宿主机的相关端口没有被占用,如:nginx, 80 & 443
- 实践验证:
- 如果创建一个Ingress资源,会将相关信息(nginx)写入到所有的已经安装的Ingress Controller中
- ingress-nginx可进入相关pod查看 cat nginx.conf, 可以看到定义的host & paths
Ingress https, tls
1 | 生成 tls.key |
1 | 编辑 |
1 | # ingress-tomcat-tls.yaml |
存储卷
基础
Pod存储卷
- emptyDir pod 临时存储空间
- hostPath 宿主机上
- 网络存储:
- SAN: iSCSI,..…
- NAS: NFS,CFS
- 分布式存储:
- glusterfs
- rbd - ceph块存储
- ==cephfs== - ceph文件存储
- 云存储:
- EBS
- AZure Disk
emptyDir
Container 中的命令行 & 参数:
- comman
- args
gitRepo
建立在emptyDir基础上
NFS存储卷
创建 NFS Service
1 | Centos NFS |
手动验证
1 | mount |
应用示例
1 | apiVersion: v1 |
PV & PVC & StorageClass
解释
PV PersistentVolume
PVC PersistentVolumeClaim
PV & PVC 区别
- PV属于==集群==级别,.yaml文件不能定义namespace
- PVC属于==namespace==级别
- 所谓集群级别,就是不能定义在名称空间中
StorageClass
- 存储提供 Restfult 管理接口,可以动态生成 PVC, StorageClass
- ==Ceph== 支持
Tips
- 只有 Pod 存储在节点( Node )上,其它 k8s 资源存储在 api-server 的状态存储 etcd 上,api-server 通过Restful 提供服务
- PV 回收策略 - persistentVolumeReclaimPolicy
ConfigMap
容器传配置信息
- 环境变量
- 特殊的存储卷 - ConfigMap
配置容器化应用的方式
- 自定义命令行参数 command & args
- 配置文件做镜像(不推荐)
- 环境变量
- Cloud Native的应用程序一般可以直接通过环境变量加载配置
- 通过entrypoint脚本来预处理变量为配置文件中的配置信息
- 存储卷
Secret
分类
- docker-registry Create a secret for use with a Docker registry
- generic Create a secret from a local file, directory or literal value
- tls Create a TLS secret
示例
- 创建Secret
1 | kubectl create secret generic mysql-root-password --from-literal=password=MyP@ss123 |
- 输出yaml, mysql-root-password $\rightarrow$ TXlQQHNzMTIz
1 | kubectl get secret mysql-root-password -o yaml |
- Base64解密,是不严格意义上的“加密”,应该是由k8s集群的rbac来控制
1 | echo TXlQQHNzMTIz | base64 -d |
- 创建pod
1 | kubectl apply -f pod-secret-1.yaml |
1 | apiVersion: v1 |
- 环境变量可以读取password内容
1 | kubectl exec -it pod-secret-1 -- printenv | grep MYSQL |
控制器 StatefulSet
在Kubernetes中,StatefulSet被用来管理有状态应用的API对象。StatefulSets在Kubernetes 1.9版本才稳定。StatefulSet管理Pod部署和扩容,并为这些Pod提供顺序和唯一性的保证。
- 与Deployment相似的地方是,StatefulSet基于spec规格管理Pod;
- 与Deployment不同的地方是,StatefulSet需要维护每一个Pod的唯一身份标识。这些Pod基于同样的spec创建,但互相之间不能替换,每一个Pod都保留自己的持久化标识。
场景
- 稳定、唯一的网络标识
- 稳定、持久的存储
- 按照顺序、优雅的部署和扩容
- 按照顺序、优雅的删除和终止
- 按照顺序、自动滚动更新
限制
- 在Kubernetes 1.9版本之前是beta版本,在Kubernetes 1.5版本之前是不提供的。
- Pod存储由PersistentVolume(storage类或者管理员预先创建)提供。
- 删除或者缩容StatefulSet不会删除与StatefulSet关联的数据卷,这样能够保证数据的安全。
- 当前的StatefulSets需要一个==Headless==服务来为Pod提供网络标识,此Headless服务需要通过手工创建。
组件
下面是一个StatefuleSet组成的示例:
- 一个名称为nginx的Headless服务,用来控制网络域。
- 一个名称为web的statefulSet,它拥有nginx容器(在唯一的Pod启动)的3个副本集。
- 使用PersistenVolumes(由PersistentVolume Provisioner提供)提供稳定存储的volumeClaimTemplates。
1 | apiVersion:v1 kind:Service |
Pod选择器
必须设置StatefulSet的sepc.selector,以匹配.spec.template.metadata.labels。在Kubernetes 1.8之前,spec.selector是可以忽略的,它被设置一个默认值。在1.8或者后续的版本,如果不设置sepc.selector,则会导致创建StatefulSet失败。
Pod身份标识
StatfuleSet Pod拥有一个唯一的身份标识,它由顺序、稳定的网络标识和稳定的存储所组成。此身份标识一直跟随着Pod,不过它被调度到那个Node上。
Tips
命令行扩容|缩容的2种方式
1 | kubectl scale sts myapp-sts --replicas=4 |
滚动更新
rollingUpdate,如果image pull出现错误
- sts 只在 partition 指定的最后一个(或者应该叫做更新的第一个)pod 出现错误提示,然后就停止更新
- sts 可以
- kubectl rollout undo sts/myapp-sts
- 删除错误的 pod,会回到之前的状态,running
sts 如果一切正常,会按倒序逐一更新,达到 stateful 的目的
1 | 设置 partition = 2 |
其它
- StatefulSet 定义中,headless service 必须指明
- volumeClaimTemplate 可以自动创建 pvc, 并绑定至合适的 pv
- StatefulSet Pod 复本的名称不是 base64 码,而是有顺序的 -1,-2,-3,..…
- 创建时顺序创建
- 删除时逆序删除
- 删除StatefulSet后,自动创建的 pvc 不会被删除,重新创建 StatefulSet 后绑定到同一个pvc, 也就是重建后数据不会变
- headless service 中 pod 的解析路径:
- pod_name.service_name.ns_name.cluster.local
- 不同于普通的pod, 无头服务的pod解析要加上service_name
认证
基础
- ==认证==
- 对称密钥:通过密钥信息认证
- SSL:还能确认 Serve r的身份
- k8s:需要双向认证,不但要确认 Server 身份,而且还要确认 Client 身份
- ==授权==
- ABAC 基于属性
- WEBHOOK
- RBAC 最主要的授权方式, 默认全部拒绝, v1.6 之后
- ==准入控制==
- 当前授权操作涉及到的其它资源的授权检查
- k8s 认证、授权、准入控制都是以 ==addons== 来实现,可以灵活定制
- k8s 有多个认证机制时,只要通过其中一项认证,即为通过认证
- 版本区别
- alpha: 内测版本,有可能大的变动或废弃,不会对外使用
- beta: 可以对外使用,与stable相比,可能会有微小变动,如:属性多一个少一个,接口描述不同等
- stable: 稳定版本
客户端 $ \rightarrow $ API Server
- user: username, uid | group | extra
- API Request path
- http://主节点/apis/apps/namespace/default/deployments/myapp-deploy/
- kubectl api-versions
- kubectl 以 cluster-admin 身份运行时,认证信息在 .kube/config 中
- kubectl启动proxy, proxy与api-server认证,再用curl与proxy通信,就不需要认证了
- kubectl proxy —port=8080
- api-server访问路径(restful):
- curl http://localhost:8080/api/v1/namespaces
- 群组级别,才可以用 api/v1 … ?
- curl http://localhost:8080/apis/apps/v1/namespaces/kube-system/deployments/kube-dns
- 命名空间级别,apis/apps/v1(具体版本)/namespaces(复数)/kube-system/资源类别(如:deployments[复数])/资源名
- HTTP request verb:
- get, post, put, delete
- API request verb:
- get, list, create, update, patch, watch, proxy, redirect, delete, deletecollection
- Resource, Subresource, Namespace, API group:
分类
- api-server需要认证客户端!
- 2 类客户端
- 外部,如:kubectl, 通过 .kube/config 信息
- 内部,如:pod,
- 2 类用户
- 人
- serviceAccountName
- 每个 namespace 都有一个默认的secret
- kubectl get secret -n ( default, kube-system, ingress-nginx, ..… ) # default-token-jvx6s
- 提供默认的认证机制,使每一个pod都可以连接至 api-server
- 默认的 token, 只认证 pod 本身,权力很小,如果想要扩展,比如:pod 本身就是一个管理类的应用,做法:
- 创建 serverAccount
- 设置 serviceAccountName
- secret 有 3 种形式
- generic
- tls
- docker-registry 关于在私有仓库中 docker pull image 时的认证信息,有 2 种方式
- 可以采用上述secret - docker-registry方式,pods.spec. imagePullSecrets
- 也可以用servic account, 将认证信息写入sa, pods.spec. serviceAccountName
自建CA & 认证自定义User
- “/CN=xxx”, xxx就是user name
1 | 创建 private key |
授权
基础
授权插件:Node, ABAC, ==RBAC==, Webhook
用户
角色
许可(Permission)
Object URL:
- /apis/
/ /namespaces/ / /[OBJECT_ID>] 对象
- role
- rolebinging
- clusterrole
- clusterrolebinding
k8s
- 对象 ( Object 大部分 )
- 对象列表 ( ObjectList )
- 虚对象 ( URL ..… )
创建用户 & 授权
==Create User With Limited Namespace Access==
示例 1
1 | 创建 namespace |
1 | kind: Role |
示例 2
创建用户
1 | openssl genrsa -out manager.key 2048 |
授权
1 | # vim deployment-manager.yaml |
1 | # vim deployment-manager-binding.yaml |
系统默认安装的ClusterRole
查看
1 | kubectl get clusterrole |
- cluster-admin 集群管理员,最高权限
- admin 名称空间管理员,可以用 rolebinding 绑定此 clusterrole, 从而获得名称空间的管理员权限
- rolebinding 属于名称空间(namespace) 级别,clusterrolebinding 属于集群级别
- rolebinding 可以绑定 role, 也可以绑定 clusterrole; clusterrolebinding只能 clusterrole
- rolebinding 绑定 clusterrole, 获得 namespace 级别的相应权限
k8s集群管理员权限从何而来?
- 绑定组
1 | kubectl get clusterrolebinding cluster-admin -o yaml |
可以看到,clusterrolebinding cluster-admin 绑定到一个组 ==system:masters==
1 | apiVersion: rbac.authorization.k8s.io/v1 |
- 查看客户端Cert
1 | openssl x509 -in admin.pem -text -noout |
在我手动创建的集群上,客户端Cert应该在 /etc/kubernetes/ca/admin, 可以看到
1 | O=system:masters |
- 授权绑定 3 种:
- user
- group
- serviceaccount
补充参考
Configure RBAC In Your Kubernetes Cluster
Dashboard
Dashboard (一)
kubernetes 认证、授权
API Server: subject —> action —> object
认证方式
- token
- tls
- user/password
账号分类
- UserAccount,
- ServiceAccount
授权方式
RBAC $\longrightarrow$ role, rolebinding, clusterrole, clusterrolebinding
Subject & Object & Action
Subject
- user
- group
- serviceaccount
Object
- resource
- resource group
- non-resource url
Action
- get
- list
- watch
- patch
- delete
- deletecollection
- …..…
Dashboard (二)
安装
1 | apply -f kubernetes-dashboard.yaml |
认证 ( 登录 ) 方式
通过Token认证
使用默认Token
直接用安装创建的默认 token
1 | Dashboard创建完成后,kube-system 名称空间生成 dashboard-admin-token-xbwgh |
自己创建Token
自己创建 serviceaccount ( sa ), 可以查看到它生成的 token, 可以控制权限
1 | 创建 serviceaccount |
生成kubeconfig文件
生成kubeconfig文件,方便分发!方便控制 dashboard 权限!
1 | set-cluster |
Dashboard (三)
Tips
认证账号
认证时的账号必须为ServiceAccount, dashboard pod拿来由k8s进行认证
token
- 创建serviceaccount, 根据管理目标,使用rolebinding或clusterrolebinding绑定至合理的role或clusterrole;
- 获取此serviceaccount的secret, 查看secret详细信息,其中有token;
kubeconfig
将serviceaccount的token封装为kubeconfig文件
- 创建sserviceaccount, 根据管理目标,使用rolebinding或clusterrolebinding绑定至合理的role或clusterrole
- 获取token
1 | SERVICE_SECRET_NAME=kubectl get secret | awk ‘/^ServiceAccount/{print $1}' |
- 生成kubeconfig文件
1 | 设置 cluster |
k8s集群管理方式
- 命令式
- create
- run
- expose
- delete
- edit
- ..…
- 命令式配置文件
- create -f
- delete -f
- replace -f
- ==【推荐】声明式配置文件==
- apply -f
- patch
调度器
Tips
- api-server 认证/查证没有问题 $\rightarrow$ scheduler $\rightarrow$ schedule 决定用哪个 node
- scheduler:
- nodeName & nodeSelector
- Pod : affinity & enti-affinity 亲和性 & 反亲和性
- 污点 & 容忍度 Tains & Tolerations
预选策略
- CheckNodeCondition
- GeneralPredicates
- HostName: 检查pod对象是否定义了pods.spec.hostname
- PodFitsHostPorts: pods.spec.containers.ports.hostPort
- MatchNodeSelector: pods.spec.nodeSelector
- PodFitsResources: 检查pod的资源需求是否被node满足
- (no default)NoDiskConflict: 检查pod依赖的存储卷是否能满足需求
- PodTolertesNodeTaints: 检查pod上的pods.spec.tolerations可容忍的污点是否完全包含节点上的污点
- (no default)PodToleratesNodeNoExecteTaints: 开始能够容忍node污点,部署上去,后来增加了污点,是否能够容忍?
- (no default)CheckNodeLabelPresence: 检查标签的存在性
- (no default)CheckSericeAffinity:
- MaxEBSVolumeCount
- MaxGCEPDVolumeCount
- MaxAzureDiskVolumeCount
- CheckVolumeBinding:
- NoVolumeZoneConflict:
- CheckNodeMemoryPressure
- CheckNodePIDPressure
- CheckNodeDiskPressure
- MatchInterPodAffinity
优选函数
- LeastRequested
- (cpu((capacity-sum(requested))*10/capacity)+memory((capacity-sum(requested))*10/capacity)) / 2
- BalancedResourceAllocation
- cpu和memory资源被占用率相近的胜出
- 评估单节点的使用率
- 和LeastRequested配合使用
- NodePreferAvodiPods 根据节点的注解信息判定 scheduler.alpha.kubernetes.io/preferAvoidPods, 如果没有前面注解,得10分,优先级为10000,很高~
- TaintToleration 将 pod 对象的 spec.tolerations 与节点的 taints 列表项进行匹配度检查,匹配的条目越多,得分越低
- SelectorSpreading 散开到更多的节点上
- InterPodAffinity 匹配的条目越多,得分越高
- NodeAffinity 节点亲和性
- (no default)MostRequested 与 LeastRequested 相反,尽可能将一个node资源先用完
- (no default)NodeLabel 只关注标签,存在就得分
- (no default)ImageLocality 根据满足当前pod对象需求已有image体积大小之和来算
高级调度
Node | Pod $\rightarrow$ affinity | antiAffinity
名词
- 节点选择器:nodeSelector, nodeName
- 节点亲和调度:nodeAffiniity
1 | kubectl explain pods.spec.affinity.nodeAffinity |
node亲和性调度
1 | preferredDuringSchedulingIgnoredDuringExecution # 软亲和性 |
pod亲和性调度
- 为什么用node亲和性能做到,还要有pod亲和性? 因为
- node亲和性要求严格定义node标签
- 可以随机调度一个pod,其它pod用亲和性处理,方便
- 调度
- 可以将机器按机架打标签,例如:rack1, rack2, rack3, …
- 然后,rack=rack1, row=row1, ..…
示例
1 | apiVersion: v1 |
Taint 污点调度
标签方式
- labels
- annotations
- 污点(只能在node上) - 让node拒绝pod
1 | kubectl explain node.spec.taints |
效果
taint的effect定义对pod排斥效果
- NoSchedule: 仅影响调度过程,对现存的pod不产生影响,即:后加的污点不影响
- NoExecute: 同时影响现存的pod,如果不容忍的pod,会被驱逐!
- PreferNoSchedule: “最好不”
关系
node 定义 taints, 污点
pod 定义 Tolerations 容忍度
1 | 示例 CriticalAddonsOnly ??? |
资源需求、资源限制
解释
容器的资源需求,资源限制(一般称为pod的…)
- requests: 需求,最低保障
- limits: 限制,硬限制
1 | kubectl explain node.spec.taints |
计量单位
CPU
- 1颗逻辑CPU = 1000 m
- m 是 millicores ( 微核 )
- 示例:500 m = 0.5 CPU
Memory
- E P T G M K
- Ei Pi Ti Gi …
服务质量 QoS
定义
Guranteed
同时设置CPU和内存的requests和limits相同, 优先级别最高!
- cup.limits=cup.requests
- memory.limits=memory.request
Burstable
至少有一个容器设置了cpu或内存资源的requests属性,中等优先级
BestEffort
没有任何一个容器设置了requests或limits属性,最低优先级
作用
按占用量和需求量的比例来定义,当资源紧张时,如果删除相应的pod
统一的资源指标收集,HeapSter ( deprecated )
资源指标API & 自定义
解释
资源指标:metrics-server
自定义指标:prometheus, k8s-prometheus-adapter
Tips
- 1.8 之前,api-server 不负责提供资源指标api, 后版本由api-server统一提供
- api-server提供的资源指标api还是很弱的,系统只能根据cup用量来伸缩,如果要通过其它方式,如:io,memeory… ,api-server就力不从心
- 其它项目,如:prometheus
新一代架构
- 核心指标流水线:由kubelet, metrics-server以及api server提供的api组成;
- cpu累积使用率
- memory实时使用率
- pod资源占用率
- container资源占用率
- 监控流水线:用于从系统收集各种指标数据并提供终端用户、存储系统以及HPA,包含:
- 核心指标
- 非核心指标 (不能被k8s解析,如: prometheus的非核心指标数据,k8s不能理解,所以需要k8s-prometheus-adapter)
Metrics-server
概念
kubernetes/cluster/addons/metrics-server 是可用的、稳定版本, 其它addons也一样
for file in metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml auth-delegator.yaml auth-reader.yaml; do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/metrics-server/$file; done
Tips
- kubectl apply -f . # apply 目录下所有的文件
- 用kubectl proxy来验证
- kubectl proxy —port=8080
- curl http://localhost:8080/apis/metrics.k8s.io/v1beta1
- curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/nodes
- curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/pods
- 用kubeadm安装的k8s集群,addons/metrics-server仍然有错误,因为:
- kubeadm认为http://..…:10255不安全,默认关闭了此端口, 必须启用https, 如下
\1. 在metrics-server-deployment.yaml中修改:
containers -> name: metrics-server -> command:
- —source=kubernetes.summary_api:https://kubernetes.default?kubeletHttps=true&kubeletPort=10250&insecure=true
\2. resource-reader.yaml 中修改:
rules -> resources -> - nodes/stats
Prometheus
docker log 目录:/var/log/containers
- prometheus在node上的代理: node_exporter
- prometheus的强大接口: PromQL, restful风格的查询接口
- Custom Metrics API -> k8s-promethues-adapter
promethues本身是个stateful应用,需要StatefulSet, 但因为StatefulSet要设置pv&pvc,为了简化演示可以用Deployment来代替
https://github.com/iKubernetes/k8s-prom
kubectl get all -n prom
HPA
Basic
- 2个版本,v1只支持核心指标,
- 如果 kubectl api-versions, 有下面的内容,则 autoscaling 被支持
- autoscaling/v1
- autoscaling/v2beta1
kubectl run myapp -–image=ikubernetes/myapp:v1 -–replicas=1 -–requests=’cpu=50m,memory=256Mi’ -–limits=’cpu=50m,memory=256Mi’ -–labels=’app=myapp’ -–expose -–port=80
kubectl run -–generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run -–generator=run-pod/v1 or kubectl create instead.
service/myapp created
deployment.apps/myapp created
测试验证hpa&v2
Tips & TODO
- autoscaling from 1 to 10 -> ok!
- rke’s k8s, kubectl get hpa -> ok,kubectl get hpa myapp-hpa-v2找不到资源?
步骤
定义myapp-requests-limits.yaml
1 | … |
定义hpav2
1 | apiVersion: autoscaling/v2beta1 |
ab压力测试
1 | ab -c 100 -n 500000 http://192.168.1.70:30888/index.html |
Helm
基础
核心术语
- Chart 一个Helm程序包
- Repositoty Charts仓库, https/http服务器
- Relese 特定的Chart部署于目标集群上的一个实例
工作流程
Chart $\longrightarrow$ Config(值文件,配置信息) $\longrightarrow$ Release
程序架构
- Helm: 客户端, 管理本地Chart仓库, 管理Chart, 与Tiller服务器交互, 发送Chart, 实例安装、查询、卸载等操作
- Tiller: 服务端, 接收Helm发来的Charts与Config,合并生成Release
Tips
- Helm init 会在k8s集群自动生成 Tiller
- Helm 用 ~/.kube/config 的认证信息
安装
创建 ServiceAccount & ClusterRoleBinding
1 | apiVersion: v1 |
Helm init ..…
1 | helm init --upgrade \ |
使用
常用命令
release管理: install, delete, status, upgrade/rollback, list, history
chart管理: create, fetch(下载压缩包并展开)/get, inspect(查看chart详细信息), package, verfy
values.yaml
- ~/.helm/cache 展开相应的应用, 有默认的 values.yaml
- copy values.yaml to {your-dir}, modify
- Tips:
- 如果安装prometheus, 则应该启用values.yaml中的==metrics==, 以便监控
- 如果启用metrics,则以下项要记得启用
2
3
4
5
6
7
8
9
10
11
enabled: false
image: oliver006/redis_exporter
imageTag: v0.11
imagePullPolicy: IfNotPresent
resources: {}
annotations:
prometheus.io/scrape: "true" # 记得启用~
prometheus.io/port: "9121"
Tips
1 | helm repo list |
安装 EFK
4大addons, 及必须的日志系统
Kubernetes必须的4大addons, 及必须的日志系统:
- addons: CoreDNS(KubeDNS) & kube-proxy
- addons: Ingress
- addons: Metrics-Server Prometheus | HeapStr 监控系统
- addons: Dashboard
- EFK | ELK 日志系统
Tips
- 每个节点上的容器的日志,会放到 /var/log/containers/ 目录下
- x-pack: Elstic 官方打包的 Elsticsearch & logstash
- helm delete —purge xxx -> 完全删除charts
问题解决
问题
ERROR ==> Invalid kernel settings. Elasticsearch requires at least: vm.max_map_count = 262144
解决
1 | 查看是否有此设置 |
利用 cirros (3Mb) 小系统镜像,测试Elasticsearch
1 | kubectl run cirros-$RANDOM --rm -it --image=cirros sh |
基于k8s的PaaS平台
- CI ( continuous integration )
- 程序员 -> 开发代码
- 推送代码 -> 仓库
- CI工具 -> 拉取代码 -> (测试环境)部署前测试
- CI工具 -> QA
- CD ( continuous delivery )
- QA -> 运维工程师
- 运维工程师 -> 部署后测试
- CD ( continuous deployment )
- 运维工程师 -> 蓝绿、灰度、金丝雀 -> (生产环境)部署
版本控制系统: Git, SVN
CI工具: Jenkins, Gitlab CI,
构建工具: Maven, Gradle, Make, …
测试工具: Junit,
部署工具:
配置工具:
工件仓库: DockerHub, JFrog,
运行环境: AWS, OpenShift(PaaS), Kubernetes, Rancher,
监控环境: Elasticsearch, Prometheus, ..…
生产环境下的Kubernetes
架构
TODO : Markdown画的图,再改~
1 | graph BT |
高级
- master高可用: kubeadm
- Kubernetes Federation: 2个集群,可同时部署,双机房备份
- priorityClass 高版本支持
- limitRange: 设置namespace默认的限制
- PSP pod security policy
- SecurityContext 设置 pod 安全上下文